
Duplikacja treści – największy wróg SEO
Spis treści:
- Co to jest powielenie treści?
- Powielenia wewnętrzne
- Powielenie zewnętrzne
- Co grozi za powielenie treści na stronie?
- Czy każda zduplikowana treść jest powielona?
- Przykłady powieleń treści
- W jaki sposób Google rozpoznaje powielenia treści?
- Jak sprawdzić, czy mamy do czynienia z powieloną treścią?
- Podsumowanie
Powielanie treści jest jednym z często spotykanych przykładów błędów znajdowanych w czasie analizy strony internetowej w ramach procesu pozycjonowania. Jest to dość złożony problem, którego przyczyny nie są czasami łatwe do ustalenia.
Z tego artykułu dowiesz się:
- co to są powielenia treści i jakie powielenia wyróżniamy,
- czy powielenie treści jest szkodliwe,
- jakie są przykłady powieleń treści, a co nią nie jest,
- jak ręcznie sprawdzić, czy dana treść jest powielona.
Czasy się zmieniają, treść na stronie też. Użytkownicy, którzy według danych z analityki internetowej tylko skanują tekst i oglądają obrazki, wcale nie są tacy mało wymagający. Wręcz przeciwnie – wymagają od treści artykułu zdecydowanie więcej. Jeżeli dany tekst im nie odpowiada, automatycznie spędzają na stronie mniej czasu i przyczyniają się do wzrostu współczynnika odrzuceń.
Obecnie spotykamy coraz mniej spektakularnych przykładów powieleń treści na stronie. Klienci, którzy są proszeni o przygotowanie treści na stronę a w efekcie dostarczają tekst z Wikipedii bez żadnych modyfikacji, też już się często nie zdarzają. Problem powieleń treści jednak istnieje i … ma się dobrze.
Co to jest powielenie treści?
Powielenie treści to celowe lub nieumyślne skopiowanie fragmentu treści z innej strony internetowej (lub z własnej strony wskutek błędu lub umyślnego działania). Takie działania są najczęściej efektem nieznajomości oprogramowania strony lub braku wiedzy dot. działania wyszukiwarki Google.
Powielenia na stronach internetowych rzadko mają na celu manipulowanie rankingiem wyszukiwania – aby to uzyskać trzeba mieć odpowiednią wiedzę i umiejętności.
Powielenie treści może występować w sposób umyślny, gdy dochodzi do skopiowania fragmentów treści i lekkiej jej modyfikacji. Dzieje się tak najczęściej, gdy właściciel strony nie ma czasu i chęci na tworzenie nowych treści. Wielokrotnie spotykaliśmy się z sytuacją, w której klient dostarczał treść na podstrony, a po jej analizie okazywało się, że jest skopiowana ze stron konkurencyjnych czy ze wspomnianej wyżej Wikipedii. Warto w tym miejscu, w ramach dygresji, wspomnieć o przypadku, gdy w czasie analizy strony znaleźliśmy skopiowany od konkurencji regulamin sklepu internetowego. Kopiujący go nie zmienił nawet nazwy firmy, adresu czy numeru telefonu…
Tak jaskrawe przykłady powielenia treści są już najczęściej przeszłością, a te wspomniane mają już kilka lat. Rośnie też wiedza klientów o powieleniach i ich konsekwencjach. Czasy, gdy klient był mocno zaskoczony, gdy zobaczył z jakiej strony skopiował fragment treści już minęły, niemniej jednak nadal zdarza się, że użytkownicy internetu nie wiedzą w jaki sposób sprawdzić, czy dana treść jest powielona. Poniżej pokazujemy, w jaki sposób można to zrobić. Zanim do tego przejdziemy, powinniśmy jeszcze dokonać kategoryzacji powieleń treści.
Powielenia wewnętrzne
Powielenie treści jest jednym z często spotykanych przykładów błędów znajdowanych w czasie analizy strony internetowej w ramach procesu pozycjonowania. Jest to dość złożony problem, którego przyczyny nie są czasami łatwe do ustalenia.
Wnikliwi czytelnicy tego wpisu zapewne zauważyli, że powyższy akapit stanowi powielenie wstępu artykułu. Został on tutaj użyty celowo, aby zobrazować zjawisko powielania wewnętrznego.
Powielenie wewnętrzne treści na stronie internetowej występuje wówczas, gdy fragment treści (lub jego całość) jest powielony w obrębie danej domeny lub podstrony.
Powielenie zewnętrzne
Zjawisko to ma miejsce wówczas, gdy kopia naszej treści znajduje się na zewnętrznych stronach www znajdujących się w innej domenie niż nasza. Mogą to być strony konkurencji, strony informacyjne, katalogi lub narzędzia, które automatycznie pobierają treść ze strony.
Co grozi za powielenie treści na stronie?
Czy powielenie treści na stronie internetowej jest w ogóle groźne? Oczywiście, że tak! Sam proces kopiowania tekstów, nawet gdyby był wykonany w sposób niecelowy, może być obarczony karą od Google. Możliwe są trzy scenariusze:
- Google uzna, że strona nie ma na tyle innej wartości dodanej, że nawet nie wyświetli jej w wynikach wyszukiwania na daną frazę. Użytkownik szukający strony, nawet gdy skopiuje fragment z jej treści, nie odnajdzie danej podstrony.
- Na stronę / podstronę / frazę zostanie nałożony filtr ręczny (ręczne działania antyspamowe). Jest to dość rzadkie zjawisko. Dochodzi do niego, gdy w Google Search Console, w zakładce „działania ręczne” otrzymamy informację od Google, że na stronę została nałożona kara. Dotyczy to skrajnych przypadków, gdy strona składa się głównie ze skopiowanej treści, która jest synonimizowana. Taka niskiej jakości treść może spowodować nałożenie kary ręcznej od Google.
- Na stronę / podstronę / frazę zostanie nałożony filtr algorytmiczny. Wszystko to za sprawą algorytmu Google Panda, który odpowiada za karanie i nagradzanie stron i skupia się na aspektach treściowych.
Algorytm Panda wymusił na właścicielach stron internetowych konieczność dbania o zawartość strony, zwłaszcza jeśli chodzi o unikalność i długość treści na podstronach. Kara wymierzona przez algorytm polega na obniżeniu pozycji danej strony / podstrony na dane słowo kluczowe lub grupę fraz. Obniżenie może wystąpić o kilka pozycji lub strona może zostać przesunięta bardzo daleko w głąb rankingu dla danej frazy.
Panda karze strony internetowe, które powielają treść z innych stron w sieci bez dodania wartości merytorycznej dla kopiowanych treści. Zwraca też uwagę na aktualność treści oraz nasycenie fraz kluczowych. Jest wyczulona na automatycznie generowaną treść na podstawie contentu z innych serwisów internetowych.
Kary za powielenie treści są dla właścicieli stron bardzo dotkliwe. Nagły spadek ruchu organicznego oraz spadek pozycji czy długofalowy i trudno odwracalny spadek widoczności w organicznych wynikach wyszukiwania skłaniają do dbania o jakość i ilość treści oraz cykliczne przeprowadzanie audytów treści nie tylko dla kluczowych podstron serwisu.
John Mueller z Google poinformował, że samo powielenie treści nie powoduje spadków pozycji i nie jest negatywnym czynnikiem rankingowym. Należy jednak pamiętać o tym, że fundamentem działania algorytmu Panda jest sprawdzanie, czy powielona treść ma wartość dodaną i to na tej podstawie algorytm nakłada ewentualne kary. Problemem nie jest samo powielenie, ale jego następstwa, które dotyczą spadku ilości stron w indeksie lub ograniczenia budżetu crawlowania.
Czy każda zduplikowana treść jest powielona?
Nie każda treść, która jest kopią tekstów znajdujących się na innej stronie, jest uznawana przez algorytmy Google za duplikat. W wielu miejscach pracownicy Google pokazują przykłady treści, która, pomimo mnóstwa powieleń, jest traktowana przez Google jako treść unikalna.
Najważniejszym przykładem, o którym warto tutaj wspomnieć, są opisy produktów. Google nie uznaje ich za powielenie pomimo że pochodzą od producenta i znajdują się na stronach innych sklepów. Tworzenie opisów produktowych jest dość trudne i obwarowane wieloma obostrzeniami. Często producent nie pozwala na stworzenie indywidualnego opisu swojego produktu i narzuca konieczność korzystania z treści, którą sam stworzył. Treść ta może się znajdować na stronach hurtowni, innych sklepów, Ceneo (oraz innych porównywarek produktowych) lub portalów aukcyjnych np. Allegro. W takim przypadku Google nie uzna, że jest to powielenie, ale muszą zostać spełnione następujące warunki:
- Sytuacja dotyczy tylko treści uzyskanych z jednego źródła, jeśli ktoś kopiuje indywidualny opis produktu (czyli taki jaki stworzył sobie inny sklep a nie producent) wówczas Google rozpozna powielenie
- Na stronie sklepu powinny się pojawić inne unikalne elementy treściowe takie jak blog, poradnik, FAQ, opisy kategorii itp.
Innym przykładem treści, która nie jest traktowana jako powielenie są cytaty. Google informuje, że możemy ich używać, najlepiej z zachowaniem zasady, że każdy cytat powinien mieć podanego swojego autora. Nie zawsze jednak da się w ten sposób tworzyć treść, zwłaszcza, gdy cytat ma być tylko odniesieniem lub dygresją od głównego tematu. Rozsądne cytowanie nie wpłynie negatywnie na pozycję strony. Co prawda prawo nie nakłada górnych limitów procentowych cytatu, nie ma też oficjalnych wytycznych Google w tej kwestii. Jak zwykle nie można jednak przesadzać. W celu „pomocy” mechanizmom wyszukiwarki w rozróżnieniu naszej treści od cytatu można go umieścić w znaczniku <blockquote>Tutaj treść cytatu</blockquote>.
Warto przywołać jeszcze jedną grupę tekstów, które nie będą przez algorytmy wyszukiwania uznawane za powielenie treści. Są to ogólnodostępne dane, takie jak pogoda, wyniki wydarzeń sportowych czy dane firm. W sieci jest mnóstwo serwisów prezentujących te same dane w niemal taki sam sposób. W oczach algorytmów wyszukiwarki Google nie stanowią one jednak powielenia. Oczywiście warto pamiętać, że o pozycji w rankingu dla takiej strony decyduje „wartość dodana” w postaci innej unikalnej treści oraz prowadzące do serwisu odnośniki.
Przykłady powieleń treści
Jak już wcześniej wspomniano, znaczna część powielonych treści powstaje w sposób nieintencjonalny oraz jest raczej wynikiem niewiedzy właścicieli stron niż celowym działaniem. Wśród dużych i małych stron zdarzają się różne przypadki powielenia treści. Są to sytuacje polegające najczęściej na wewnętrznej duplikacji. Wynikają one w głównej mierze z nieznajomości oprogramowania lub niedostosowaniu go do zasad SEO.
Do nieświadomego powielenia treści dochodzi najczęściej, gdy ta sama zawartość jest dostępna pod wieloma adresami. Dobrym przykładem tego zjawiska jest brak wyboru podstawowej wersji strony. Dla robota Google podstrona w tej samej domenie „bez www” jak i „z www” to dwie odrębne podstrony. Podobnie rzecz się ma, jeśli chodzi o zawartość strony dostępną pod protokołem HTTPS. Jeśli nie wybierzemy podstawowej wersji strony i nie wykonamy przekierowania z innych wersji na podstawową, wówczas ta sama treść będzie dostępna pod adresami:
- http://widzialni.pl
- http://www.widzialni.pl
- https://widzialni.pl
- https://www.widzialni.pl
Spora grupa stron powiela swoją treść pomiędzy wersją strony przygotowaną dla użytkowników korzystających z komputerów oraz wersją strony dla użytkowników mobilnych. Mowa tutaj o sytuacji, gdy strona nie posiada wersji responsywnej, a dwie odrębnie utrzymywane wersje – główną oraz mobilną (najczęściej w subdomenie m.domena.pl). Najlepszym rozwiązaniem tego problemu jest dodanie adresu kanonicznego, który wskazuje na wersję strony na desktopy. Co ważne, należy zrobić to na poziomie każdej podstrony, wskazując 1:1 lustrzaną podstronę w wersji na komputery. Dzięki temu, na stronie wyszukiwania Google dla tej samej frazy, na komputery, zobaczymy adres dopasowany do komputerów, np. domena.pl/podstrona, a na wersji mobilnej m.domena.pl/podstrona.
Często problematyczne są także subdomeny, zwłaszcza niezabezpieczone (najlepiej na hasło) subodmeny zawierające testowe wersje strony, na których programiści wprowadzają zmiany przed wdrożeniem ich na wersję produkcyjną. Innym przykładem jest też wildcard, czyli mechanizm, który pomaga w generowaniu aliasów. Niepoprawnie użyty lub skonfigurowany sprawia, że dowolna subdomena powiela całą zawartość serwisu głównego. Przykładowe adresy, które mogą spowodować powielenie:
- wwww.widzialni.pl
- jestesmy.widzialni.pl
- qwerty.widzialni.pl
Sporadycznie zdarza się, że powielenie występuje, gdy strona dostępna jest zarówno pod swoją domeną, jak i pod adresem technicznym – np. w domenie, którą dostarcza właściciel hostingu. W takim przypadku mamy do czynienia z serwisami bliźniaczymi, czyli dokładnymi klonami całej zawartości strony internetowej.
Potencjalne błędy mogą wygenerować strony testowe, niepełne lub niegotowe, które nie powinny zostać opublikowane. Zawierają one często treść z innej podstrony, która powinna być zastąpiona przez treść docelową, gdyż są pomyślane jako kopia opublikowanej wcześniej podstrony.
Strona w różnych wersjach językowych może być również powodem do niepokoju jeśli chodzi o możliwość wystąpienia powielenia treści. Zdarza się czasami, że niektóre podstrony nie są całkowicie przetłumaczone lub umieszczony jest na nich wspólny tekst, co jest oczywiście dobrym przykładem powielenia.
Dużym problemem, zwłaszcza na autorskich skryptach, może być powielenie strony głównej, która może być dostępna pod wieloma adresami. Jeśli brakuje nam przekierowania na wersję podstawową to takie działanie powoduje powielenie treści. Przykłady takiej adresacji to:
- widzialni.pl
- widzialni.pl/strona-glowna
- widzialni.pl/index.html
- widzialni.pl/index.php
- …
Powielenie treści na strony paginacji również może być uciążliwe, zwłaszcza dla sklepów internetowych. Dochodzi do niego, gdy na każdej stronie paginacji mamy pod produktami tą samą treść, która znajduje się na pierwszej stronie paginacji dla danej kategorii.
Dużym problemem są też parametry w adresie podstrony. Wynikają one np. z filtrowania, sortowania (np. produktów względem ceny, artykułów względem daty) czy też są wynikiem przekazania w adresie URL informacji z/do skryptu. Bez wskazania kanonicznej wersji strony mamy do czynienia z powieleniem np. pod takimi adresami:
- widzialni.pl/podstrona?sort=asc
- widzialni.pl/podstrona?c=8
- widzialni.pl/podstrona?filter=1
- widzialni.pl/podstrona?sort=asc&filter=1
Nie możemy także zapominać o duplikacji treści w wersji do druku lub o powieleniu tekstu pomiędzy stroną www a plikiem np. PDF, który zawiera tą samą treść. Google oczywiście indeksuje takie strony i pliki, o ile nie są w odpowiedni sposób zabezpieczone przed indeksacją.
W wielu przypadkach należy też uważać na niezablokowane przed indeksacją strony tagów czy podstrony wyszukiwarki wewnętrznej, zwłaszcza gdy oprócz odnośnika do danego wpisu czy produktu pokazują one także fragment jego treści. Podobnie rzecz się ma np. ze stronami archiwów czy autorów w CMS WordPress.
Należy pamiętać o tym, że treść może być dostępna pod dwoma adresami, gdy mamy włączony mechanizm przyjaznych adresów URL. Przykładem problemu z powieleniem treści, który powstał wskutek włączenia tego systemu jest CMS Drupal, gdzie strony są dostępne zarówno pod przyjazną wersją, jak i pod adresami np. /node/12.
Jeśli wspominamy o adresacji to warto się zastanowić w jaki sposób budowane są adresy URL, zwłaszcza w sklepach internetowych. Często zdarza się, że zawierają one pełną ścieżkę uwzględniającą stronę kategorii. Problem zaczyna się, gdy jeden produkt jest dostępny w wielu kategoriach. Czasami możliwe są dwie ścieżki (bez i z adresem kategorii). Możliwe powielenia tego samego produktu:
- widzialni.pl/produkt1
- widzialni.pl/kategoria/produkt1
- widzialni.pl/kategoria2/produkt1
Do powielenia treści mogą też doprowadzić sami użytkownicy np. poprzez umieszczenie takich samych opisów jak na firmowej stronie na stronach partnerów, w katalogach czy social media. W taki sposób można powielić treści zewnętrznie, np. wysyłając notki prasowe do redakcji i umieszczając je na swojej stronie www. Często zdarza się, że unikalne opisy produktów trafiają do Allegro, Ceneo czy na inne strony i mikroblogi niwecząc prace nad unikalną zawartością podstron.
Właściciele sklepów popełniają jeszcze jeden grzech jeśli chodzi o powielenie treści – korzystają z opisów i materiałów (wpisów blogowych, opisów serii produktów), które dostarczył producent. Prawdopodobieństwo, że wpis taki znajdzie się też na innej domenie jest dość duże, więc takie generowanie powielonej treści w serwisie nie jest dobrym kierunkiem rozwoju strony…
Na koniec tej części, jako ciekawostkę dodam, że powieleniem może też być umieszczenie całej treści kategorii w atrybucie title w odnośniku do danej kategorii w menu. Działo się tak na niektórych szablonach skryptu sklepu PrestaShop.
W jaki sposób Google rozpoznaje powielenia treści?
Algorytmy wyszukiwarki Google potrafią określić wiarygodność treści za pomocą szeregu czynników i miar, które są zbierane w czasie crawlowania i indeksowania strony internetowej przez roboty wyszukiwarki.
W pierwszej kolejności Google sprawdza, czy treść nie jest powielona. Dzieje się to z pomocą hashowania. Metoda ta pozwala na stworzenie krótkiego, losowego ciągu znaków, który będzie odpowiadał całej treści strony. Z treści dokumentu tworzony jest odpowiadający jej skrót, który następnie jest porównywany z innymi skrótami. Jeśli wynik jest taki sam, wówczas mamy do czynienia z powieleniem treści. Użycie takiej sumy kontrolnej jest znacznie łatwiejsze i szybsze (zabiera mniej zasobów) niż porównywanie dokumentów zapisanych w bazie danych wyszukiwarki.
Google nie korzysta tylko z jednej sumy kontrolnej, tworzy ich większą ilość, używając różnych kombinacji słów wpisanych na listę słów, do pominięcia, synonimów i fraz pokrewnych. Algorytmy pomijają też stałe bloki na stronie. Dzięki temu mechanizmy wyszukiwarki Google mogą rozpoznać powielenie treści nawet gdy cała treść nie jest powielona. Jeśli badany fragment nie różni się znacznie od fragmentu zapisanego w bazie, wówczas mamy do czynienia z powieleniem treści.
Podczas crawlowania zbierane są takie informacje, jak np. data crawlowania. Na tej podstawie możliwe jest określenie, kto pierwszy stworzył daną treść. Korzystając z pary czynników suma kontrolna + data crawlowania treści możliwe jest wskazanie, która ze stron może być domniemanym autorem treści. Google nie do końca sobie z tym jednak radzi. Bardzo często zdarza się, że przypisuje autorstwo treści dużemu portalowi, który skopiował treści z małej strony. Dzieje się tak przez mechanizm wyboru podstrony, która ma się wyświetlić użytkownikowi w wynikach wyszukiwania.

Według informacji z pomocy Google, wyszukiwarka posiada mechanizmy, które potrafią same wybrać jedną z wersji treści (jeden z adresów URL, pod którym treść się znajduje) i umieścić ją w indeksie wyszukiwarki. Pozostałe wersje treści trafią wówczas do indeksu pomocniczego lub nie zostaną w ogóle zaindeksowane. W tym celu z uzyskanych sum kontrolnych wykonuje się grupowanie i klastrowanie (są to metody eksploracji danych) w celu znalezienia stron podobnych. Oprócz tego, Google korzysta z sygnałów jakie daje sama strona www takich jak:
- obecność danej podstrony w mapie witryny wraz z informacją o dacie jej powstania,
- liczba i typ przekierowań dla danej podstrony,
- wskazania z/do adresów kanonicznych,
- data pierwszego zaindeksowania strony,
- linki:
- wewnętrzne i zewnętrzne linki prowadzące do strony,
- wskazania w hreflang,
- odnośniki z menu i stopki;
- podstawowa optymalizacja strony:
- uzupełnione znaczniki title i description,
- czas wczytywania strony,
- obecność https.
Ilość tych czynników sprawia, że czasem zamiast oryginalnego autora treści Google pokazuje serwis, który tą treść skopiował, gdyż ma on większy autorytet oraz lepsze parametry niż strona z której treść została skopiowana. Problem ten jest powszechny – nawet na stronach swojej pomocy Google informuje, że może on wystąpić. Pomoc zawiera też informacje co należy zrobić w takim przypadku czyli zgłoszenie kradzieży treści z pomocą ustawy Digital Millennium Copyright Act lub o samodzielnym kontakcie z właścicielami stron, które kopiują naszą treść. Oba sposoby mają dość dużą skuteczność i pozwalają na pozbycie się tego problemu.
Jak sprawdzić, czy mamy do czynienia z powieloną treścią?
Odpowiedź na to pytanie jest niezwykle prosta – użyć wyszukiwarki Google. Dzięki zasobom internetowego giganta dowiemy się, czy zamówiona przez nas treść lub opis ze strony internetowej są unikalne, czy też mamy do czynienia z powieleniami treści. Schemat działania jest następujący
- Skopiuj fragment treści ze swojej strony internetowej lub z treści otrzymanej od copywritera. Najlepiej kopiować całe zdania i zaznaczyć 8-10 wyrazów. Warto wybrać taki fragment, który ma jak najmniej spójników. Najlepiej zrezygnować też z kopiowania fragmentu treści, który zawiera dane adresowe, czy nazwę firmy. Staramy się wybrać fragment najmniej „spersonalizowany”.
- Przejdź na stronę wyszukiwarki Google – https://www.google.com/
- Wklej skopiowaną wcześniej treść w pole wyszukiwania umieszczając ją w cudzysłowach.
- Jeśli nie zobaczysz żadnych wyników lub ujrzysz tylko jeden wynik z Twojej domeny, wówczas można przyjąć, że nie doszło do powielenia treści. Jeśli jednak zobaczysz więcej niż jedną podstronę ze swojej witryny lub strony innych firm, wówczas mamy do czynienia z powieleniem treści na stronie internetowej.
Poniższy obrazek pokazuje przykład treści wklejonej do wyszukiwarki Google, gdzie nie doszło do powielenia treści – otrzymaliśmy tylko jeden wynik z jednej domeny.
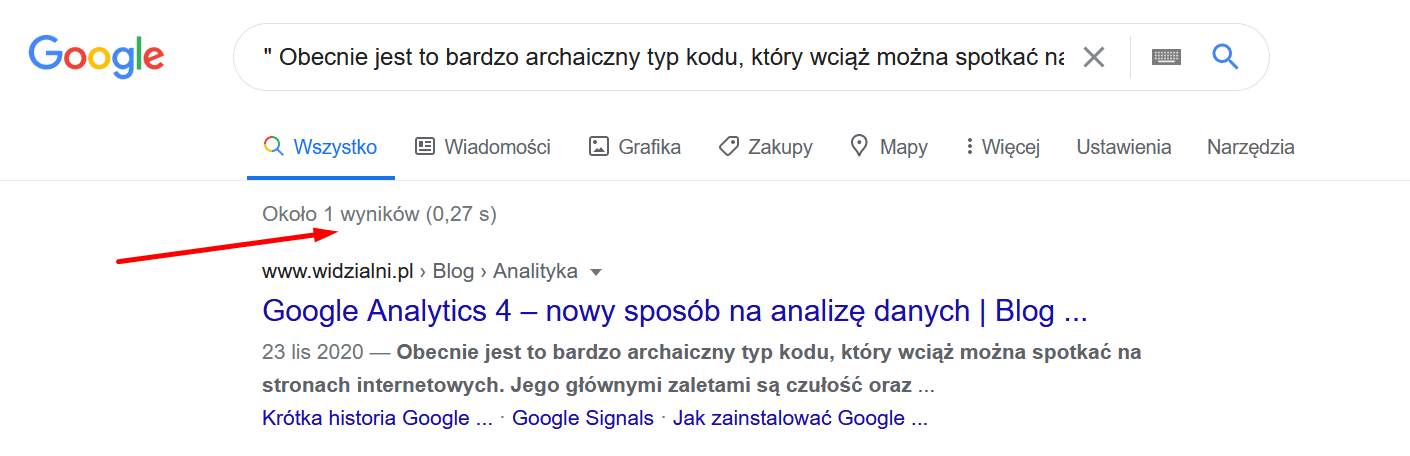
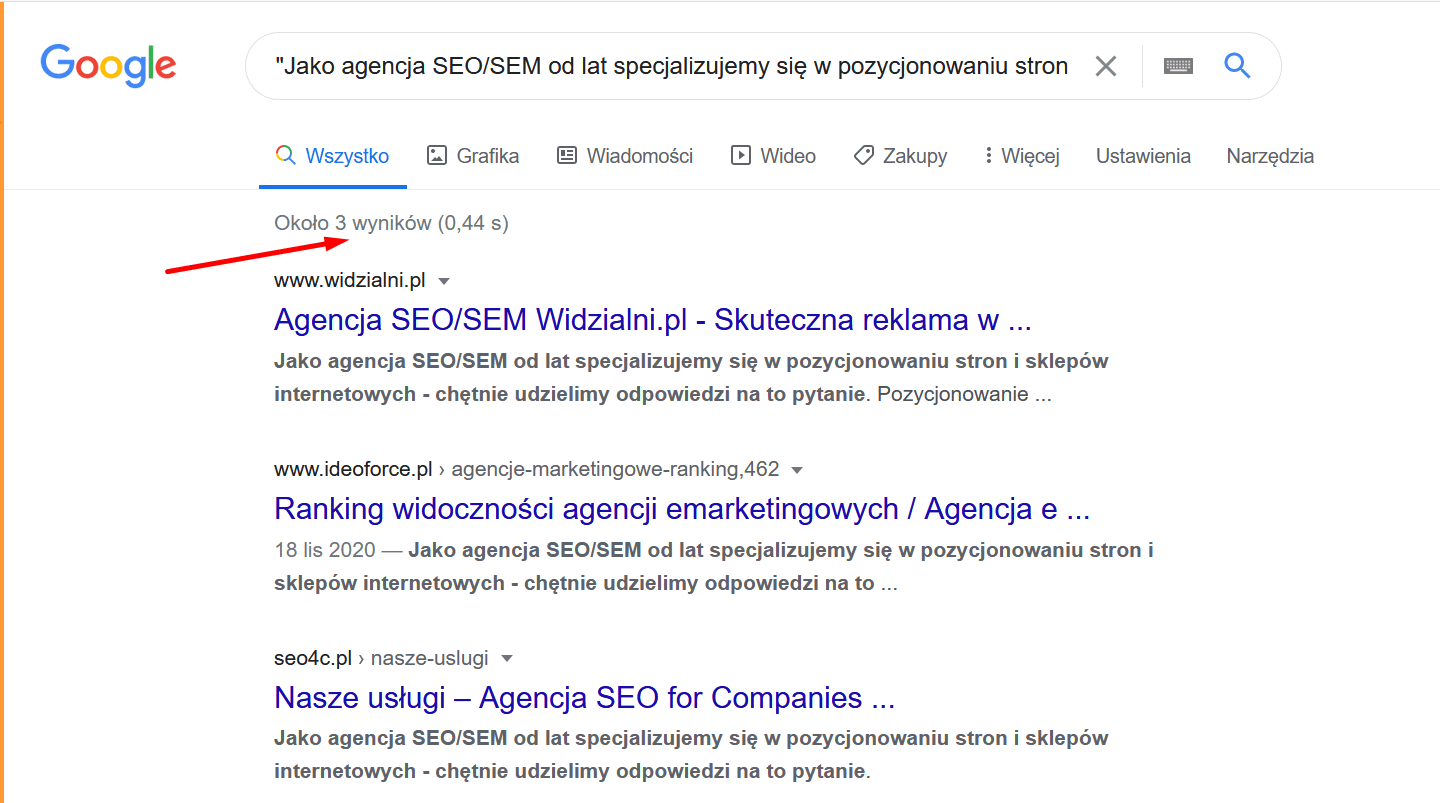
Na tym screenie pokazano przykład wyniku wyszukiwania Google, który wskazuje na problem z powieleniem treści. Przykład ten pokazuje inną firmę SEO, która skopiowała fragment naszej treści na swoją stronę internetową. Nie świadczy to o nich dobrze – jak widać nie znają nawet podstaw jednego z filarów SEO – tworzenia odpowiednio zoptymalizowanej i unikalnej treści.
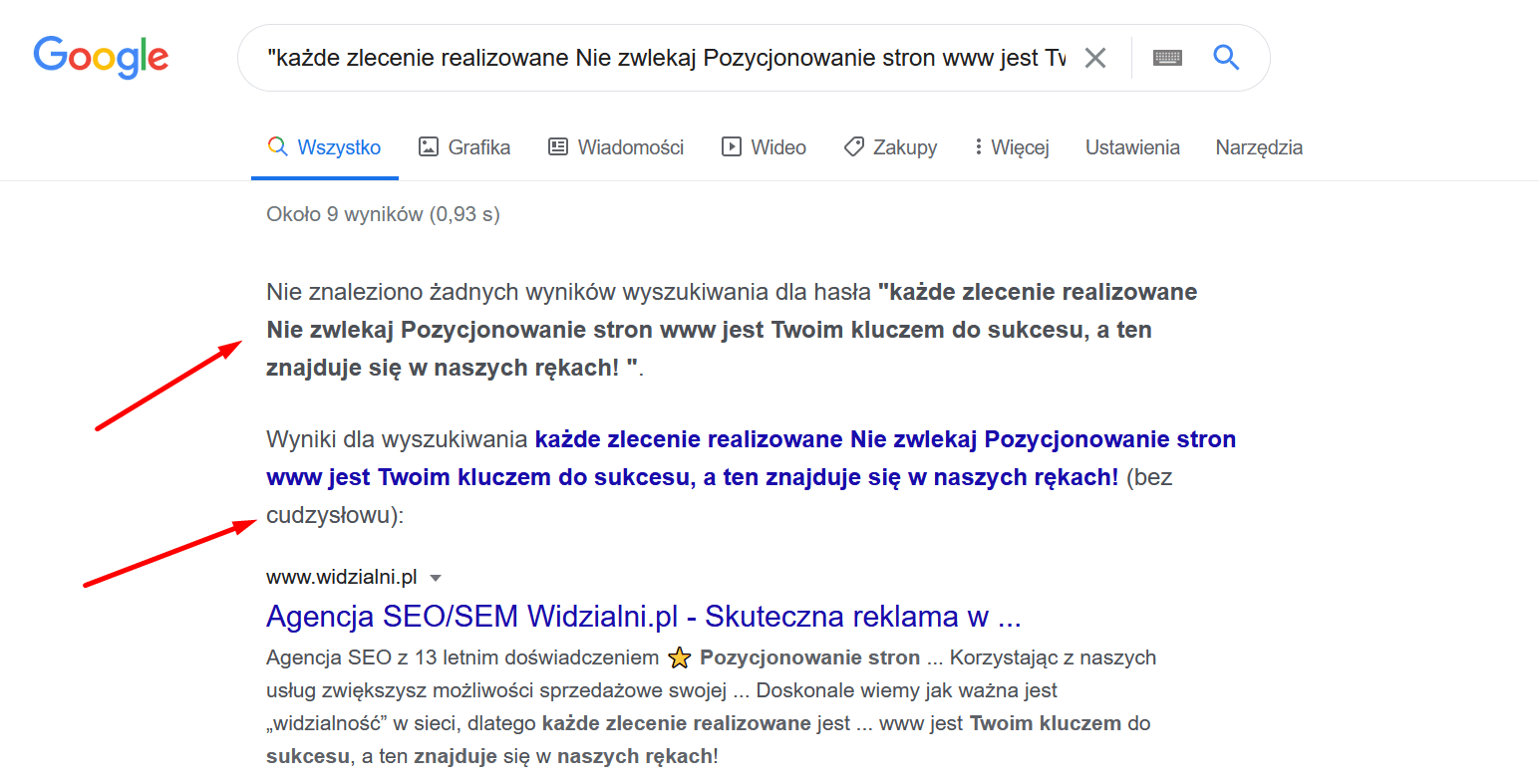
W trakcie weryfikacji unikalności treści za pomocą wyszukiwarki Google możemy się spotkać z jeszcze jedną sytuacją. Algorytm Google uzna, że nie ma wystarczającej ilości wyników aby pokazać je dla danego zapytania i zaprezentuje je bez ich użycia. Różnica jest diametralna, gdyż w takim przypadku Google inaczej dobiera podstrony, które nam pokazuje – nie powielają one naszej treści, a jedynie zawierają w swoim tekście wybrane słowa, które często nawet nie leżą obok siebie. Warto zwrócić uwagę na zaznaczony strzałką komunikat, by wiedzieć, że w tym przypadku należy wybrać inny fragment treści do analizy.
Analiza unikalności treści, na przykład z danej podstrony serwisu, powinna obejmować więcej niż jeden fragment. Warto sprawdzać losowo wybrane zdania z początku treści, z jej środka ikońca . Dzięki temu będziemy mogli sprawdzić czy treść nie jest powielona np. przez automat, który zbiera dane ze stron internetowych.
Oczywiście analiza powielenia treści za pomocą wyszukiwarki Google to nie jest jedyny sposób na to, by określić, czy dana treść jest unikalna. Można to również zrobić z pomocą dedykowanych do tego narzędzi. Jakie to narzędzia oraz jak ich w poprawny sposób użyć opiszę w kolejnej części tego artykułu.
Podsumowanie
Duplicate content to zjawisko, które może przysporzyć domenie wiele problemów. Powielona treść może spowodować, że podstrona będzie słabiej rankować na daną frazę, zostanie wyindeksowana lub przeniesiona do indeksu pomocniczego. Nadmierna ilość powielonej treści może spowodować problemy z karą od Google lub też znacznie ograniczyć budżet crawlowania dla witryny.
O unikalność treści na stronie należy zadbać w sposób szczególny za pomocą ręcznego lub automatycznego audytu treści. Jak to zrobić w sposób rozsądny, z wykorzystaniem narzędzi? O tym w kolejnych częściach tego wpisu!.
Brak sekcji

Powiązane wpisy
- Dlaczego tanie pozycjonowanie nie działa?
- Sitemap – co to jest i co warto o niej wiedzieć?
- Jak pozycjonować stronę internetową – poradnik krok po kroku
- Nagłówki H1, H2, H3 w pozycjonowaniu. Jaki mają wpływ na SEO?
- Czym są linki przychodzące i jak wpływają na SEO?
- SEO – co to jest?
- Geolokalizacja – czym jest i jaka jest jej rola w pozycjonowaniu stron?
- Czy pozycjonowanie jest skuteczne?
- 6 narzędzi dla specjalisty SEO
- ATF i BTF – czym są i co powinny zawierać?
- Linkowanie wewnętrzne w pigułce
- 6 pomysłów na wyindeksowanie strony z wyników wyszukiwania


