
Audyt powielonej treści na stronie internetowej
Spis treści:
- W jaki sposób radzić sobie z powieleniem treści?
- Powielenia treści na zajawkach artykułu
- Audyt treści na stronie internetowej
- Wytypowanie kluczowych treści witryny
- Analiza kluczowych podstron
- Analiza site oraz indeksu Google
- Kontrola wszystkich wersji witryny
- Analiza treści wspólnych
- Analiza kanałów dystrybucji
- Analiza adresacji kanonicznej
Duplikacja treści na stronie www zwykle nie zwiastuje niczego dobrego. Jest to sygnał dla Google, że jakość tekstu, a co za tym idzie – jakość strony, nie jest najwyższa. W ślad za tym sygnałem podążają też inne algorytmy Google odpowiedzialne za badanie wartości dodanej dla użytkownika. Jeśli w ich wyniku nie będzie przesłanek, że strona takie wartości oferuje, jej pozycja w rankingu może zostać obniżona.
W poprzedniej części tego artykułu dowiedzieliśmy się, co to jest powielenie treści, jakie są jego typy oraz jak ręcznie sprawdzić, czy dana treść jest unikalna. Niniejszy wpis stanowi kontynuację poprzedniego artykułu i zawiera dalsze informacje dotyczące problematyki powielenia treści na stronach internetowych.
Z tego artykułu dowiesz się:
- co robić, gdy odkryjesz na stronie powieloną treść;
- jak przeprowadzić audyt treści na stronie internetowej;
- jakie kroki podjąć, by sprawdzić treści pod kątem powielenia.
W jaki sposób radzić sobie z powieleniem treści?
W przypadku, gdy uda nam się zidentyfikować powieloną treść na stronie, musimy podjąć działania, by się jej pozbyć. Rodzaj działania zależy od przyczyny powielenia treści, a zastosowane rozwiązanie będzie korelować z problemem, który sprawił, że mamy do czynienia z powieloną treścią. W celu wyeliminowania problemów z powieloną treścią możemy:
- przeredagować powieloną treść,
- skontaktować się z podmiotem kopiującym nasze treści z prośbą o ich usunięcie,
- zablokować przed indeksacją parametry zapytań,
- skorzystać z adresacji kanonicznej i wskazać pierwowzór treści,
- wyindeksować strony, które powielają treść,
- wykonać przekierowanie 301 na podstawową wersję domeny lub strony głównej,
- usunąć treści ze stron paginacji, filtrowania,
- nie publikować niegotowych stron,
- zablokować przesyłanie opisów produktów np. do feedów porównywarek cenowych czy pasaży,
- zachować spójność linkowania wewnętrznego, wskazując wszędzie ten sam adres URL,
- nie dzielić się z innymi swoją treścią (np. uważać na wspomniane adnotacje prasowe),
- przenieść treść na osobną podstronę i podlinkować ją, zamiast umieszczać skopiowaną treść na wielu podstronach.
Powielenia treści na zajawkach artykułu
Problem, z którym się dość często stykamy, dotyczy automatycznie tworzonych powieleń z fragmentów treści. Jest to częste zjawisko, które występuje zwłaszcza na platformach blogowych np. WordPress. Występuje ono, gdy na stronie tagu, kategorii albo na stronie głównej danego bloga pokazują się fragmenty innych wpisów. Taka sytuacja ma miejsce również na naszym blogu.
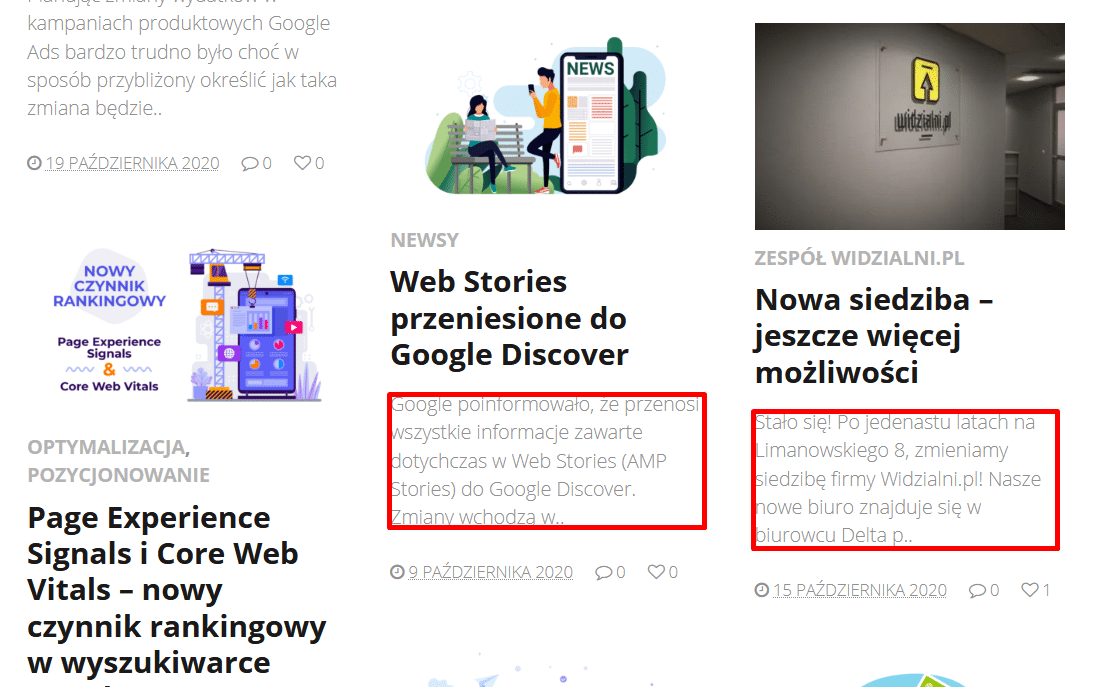
Tak zwane zajawki treści mogą być problemem jeśli chodzi o unikalność tekstów na stronie internetowej. W celu oceny tego, czy taka treść może rzeczywiście szkodzić, warto się kierować zasadą, że jeśli procent powielenia treści w stosunku do jej całości jest mały, możemy uznać, że taka powielona treść nie zaszkodzi danemu artykułowi.
Rozważyć możemy następujące scenariusze:
- Powielona treść w zajawce artykułu stanowi ponad 10-20% całej jego objętości. Wówczas może ona potencjalnie zaszkodzić temu artykułowi.
- Powielona treść w zajawce artykułu stanowi mniej niż 10-20% jego długości, wówczas można uznać, że nie powinna przyczynić się do pogorszenia pozycji artykułu na szereg fraz kluczowych.
Należy też pamiętać o jeszcze jednym aspekcie powielonych treści w zajawkach artykułów. Chodzi o to, jak wpływają one na stronę tagu lub kategorii. Bardzo często na stronach opartych o CMS WordPress możemy zauważyć sytuację, gdy na podstronie tagu lub kategorii znajduje się jedynie powielona treść kilkunastu artykułów. O ile procent powielenia jest mały, nie powinien być problemem dla samego artykułu, co wiemy już z wcześniejszej części tego wpisu, to suma takich powieleń może niekorzystnie działać na podstronę danego tagu. Taka podstrona składa się przecież jedynie z fragmentów artykułów, które stanowią ich powielenie, a sama nie ma żadnej wartości dodanej. Mechanizmy oceny Google bardzo nie lubią takich podstron.
Rozwiązania tego problemu są trzy:
- Na daną stronę nakładamy znacznik meta robots noindex z atrybutem follow. Dzięki temu robot analizuje treść podstrony, ale jej nie indeksuje. Może też przechodzić po linkach wewnętrznych do wpisów.
- Dodajemy do takiej strony „wartość dodaną”. Najczęściej będzie to unikalny opis, stanowiący podsumowanie danego tagu lub zbierający w sposób encyklopedyczny informacje na dany temat. Wówczas oprócz odnośników do artykułów blogowych mamy też inną treść, która nie jest powieleniem. Od stosunku i jakości treści unikalnej do powielonej będzie zależało to, czy Google wysoko oceni tę stronę.
- Walczymy o autorytet tej strony za pomocą działań onsite i linkowania. Odpowiednia optymalizacja oraz dobrze dobrane odnośniki zewnętrzne pomogą w zwiększeniu widoczności podstrony, co przełoży się na ocenę tej strony. Jest to rozwiązanie najtrudniejsze i wymagające odpowiedniej strategii, aby nie kanibalizować się z treściami wpisów. Takie rozwiązanie jest w chwili tworzenia tego tekstu używane na widzialnym blogu i póki co przynosi dobre rezultaty.
Audyt treści na stronie internetowej
Roboty wyszukiwarki Google w sposób cykliczny odwiedzają naszą stronę. Zbierają informacje na temat zawartości podstron oraz przekazują te dane do analizy przez algorytmy wyszukiwania i indeksowania. Dane, zebrane przez Google, dotyczące naszej strony zmieniają się dość często – dla niektórych typów stron (np. duże portale newsowe) takie zmiany mogą następować niemalże w ciągu kilku minut. Zadaniem właściciela strony powinna być kontrola i monitoring tego, co Google wie o danej stronie. W tym celu należy przeprowadzić audyt.
Zmienia się również sama treść na naszych stronach oraz na innych witrynach w sieci. W serwisie pojawiają się nowe treści, niektóre podstrony kończą swój cykl życia. Wszystkie te aspekty powinny być przedmiotem naszej analizy.
Audyt treści powinien być przeprowadzany cyklicznie. Częstotliwość jego przeprowadzenia powinna zależeć od:
- liczby stron w serwisie,
- ilości i typów treści np. strony kategorii, produktów, blogowe, informacyjne etc.,
- liczby zaindeksowanych podstron sprawdzonych komendą site:nazwadomeny.pl
- rozwiązań technicznych, a zwłaszcza od użytego skryptu lub CMSa.
Zwykle warto przeprowadzać taką analizę raz w miesiącu lub co dwa miesiące. Oczywiście przy większych lub bardziej skomplikowanych projektach taka częstotliwość nie wystarczy. Przy wyborze czasu przeprowadzenia audytu należy się też kierować względami technicznymi – wiele zależy od użytego oprogramowania, skryptu lub CMSa strony. Niektóre z nich (np. rzadko spotykana już Joomla!) potrafią generować błędy związane z powieleniem treści, więc taki audyt należy wykonywać znacznie częściej…
Wynikiem audytu strony powinna być lista działań do wykonania i wdrożenia. Najczęściej będą to wskazówki techniczne dotyczące optymalizacji podstron lub też wskazówki treściowe dotyczące konieczności stworzenia treści na nowo. Jako uwagę warto też dodać, że celem audytu nie jest sprawdzenie, czy dana treść wykorzystuje w 100% potencjał i ma odpowiednie słowa kluczowe, a jedynie sprawdzenie, czy dana treść nie jest powielona.
Audyt powinien składać się z siedmiu punktów. Część z nich można pominąć lub wykonać w większych odstępach czasu. Pozostałe warto jednak sprawdzać znacznie częściej. W ramach audytu treści należy skupić się na wytypowaniu kluczowych treści witryny i audycie kluczowych podstron.
Wytypowanie kluczowych treści witryny
Pierwszym krokiem audytu jest wytypowanie kluczowych treści dla naszej strony www. Warto się dobrze zastanowić, które teksty są dla nas najważniejsze, np. jakie kategorie lub produkty są najlepiej sprzedawane, jakie usługi generują zysk. Do tak zebranych adresów URL należy dodać te, które faktycznie generują nam ruch i konwersje, jeśli je mierzymy. W tym celu najlepiej będzie posłużyć się danymi z Google Analytics.
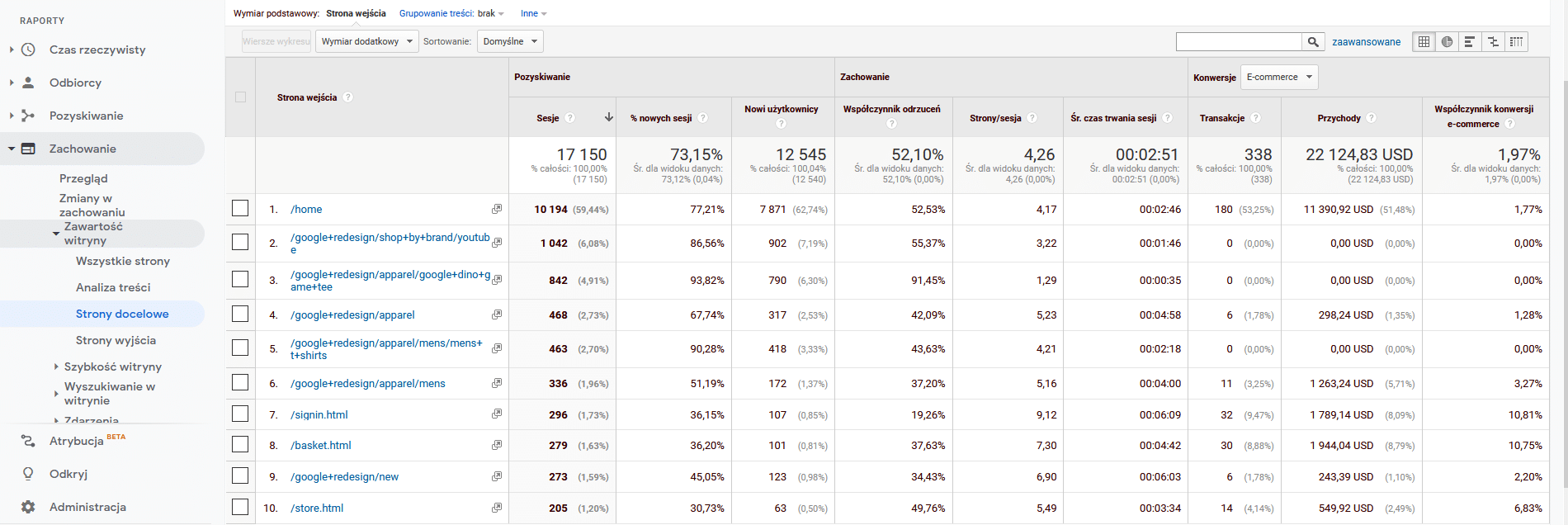
W celu odnalezienia takich stron w interfejsie Google Analytics przechodzimy do gałęzi Zachowanie → Zawartość witryny → Strony docelowe. Widok ten przedstawia strony, które generują największy ruch wyrażony w sesjach. Naszą uwagę powinniśmy zwrócić też na dwie inne metryki – przychody oraz współczynnik konwersji e-commerce. Na ich podstawie należy przygotować zbiór wyjściowy do dalszych prac.
W celu dodatkowej analizy warto zbiór zawęzić do segmentu zawierającego strony tylko z jednego kanału pozyskania np. bezpłatnego ruchu organicznego. Otrzymane wówczas dane można porównać z pierwotnym zbiorem. Często zdarza się, że dla SEO istnieje inna, specyficzna grupa podstron generujących ruch, dlatego też warto również dołączyć dane z tego kanału.
Może się zdarzyć, że nasza lista w tym momencie będzie bardzo długa, a my nie chcemy, albo nie możemy analizować aż tak dużej ilości danych. Rozwiązaniem jest nadanie ocen punktowych dla poszczególnych podstron i wybranie np. 10-20 podstron z największą liczbą punktów. Przykładowe wagi mogą wyglądać następująco:
- strona została przez nas uznana za ważna – 1 punkt;
- strona stanowi nośnik ruchu – 2 punkty;
- strona pojawia się na ścieżce konwersji – 3 punkty.
Oceny punktowe można dowolnie modyfikować. W przedstawionym przykładzie zastosowano model data-driven, przyznając więcej punktów za ruch i konwersje, niż za wrażenia empiryczne. Z doświadczenia wiem, że na tym etapie okazuje się, że Google Analytics dostarcza zupełnie innych stron, niż przypuszczają właściciele biznesów…
Analiza kluczowych podstron
Krok drugi naszego audytu to analiza wcześniej wybranych, kluczowych podstron serwisu. W pierwszej kolejności należy się upewnić, czy dana podstrona posiada w ogóle treść. Czasem dzieje się tak, że strona jest mocno osadzona w strukturze witryny i zawiera kluczowe informacje, które generują ruch, ale nie zawiera treści. Taka sytuacja ma też miejsce, gdy autorytet strony opiera się na poprawnie przeprowadzonej optymalizacji oraz linkowaniu zewnętrznym kierującym do strony. Krok ten ma na celu ustalenie, czy na wszystkich kluczowych stronach jest treść. Jeśli jej brakuje, wówczas warto ją utworzyć, aby pozyskać dla tej podstrony jeszcze więcej ruchu z organicznych wyników wyszukiwania. Oczywiście treść tą należy tworzyć zgodnie z zasadami SEO copywritingu oraz z użyciem słów kluczowych. Nie stanowi to istoty wpisu, więc nie będziemy pokazywać tego procesu.
Zasadniczą częścią audytu treści jest sprawdzenie, czy treści podstron znajdujących się w zbiorze kluczowych stron nie są powielone. Takie działania należy wykonywać regularnie dla wcześniej zdefiniowanej grupy najważniejszych podstron. Sprawdzać należy dokładnie, najlepiej kilka różnych fragmentów treści dla każdej podstrony. Istnieją dwa sposoby sprawdzania unikalności treści:
- Manualny, polegający na ręcznym sprawdzeniu w indeksie Google, czy dana treść nie jest powielona. Więcej o tej metodzie pokazano w pierwszej części tego wpisu – Duplikacja treści wrogiem SEO.
- Automatyczny, z użyciem dedykowanych do tego narzędzi. Więcej informacji o narzędziach do sprawdzania unikalności treści znajdzie się w kolejnej części wpisu.
Oba sposoby są tak samo skuteczne. Drugi z nich jest znacznie szybszy i w zależności od użycia danego narzędzia pozwala na wyciągnięcie przy okazji dodatkowych danych o badanym adresie URL.
Kiedy zakończyliśmy sprawdzanie kluczowych adresów URL pod kątem duplikacji treści, możemy przejść do następnego kroku.
Analiza site oraz indeksu Google
Należy teraz wykonać inspekcję danych, które znajdują się w indeksie wyszukiwarki Google. Jest to kolejne, ważne zadanie, które powinno być wykonywane cyklicznie. Na podstawie takiej analizy możemy odkryć anomalia, które czasem ciężko jest zauważyć, analizując podstrony naszej witryny.
Taką analizę najlepiej jest wykonać wpisując w wyszukiwarkę Google operator site:domena.pl – zastępując oczywiście słowo „domena.pl” nazwą własnej strony. Warto zwrócić uwagę na fakt, że nie wpisujemy tutaj przedrostków np. www, https etc.
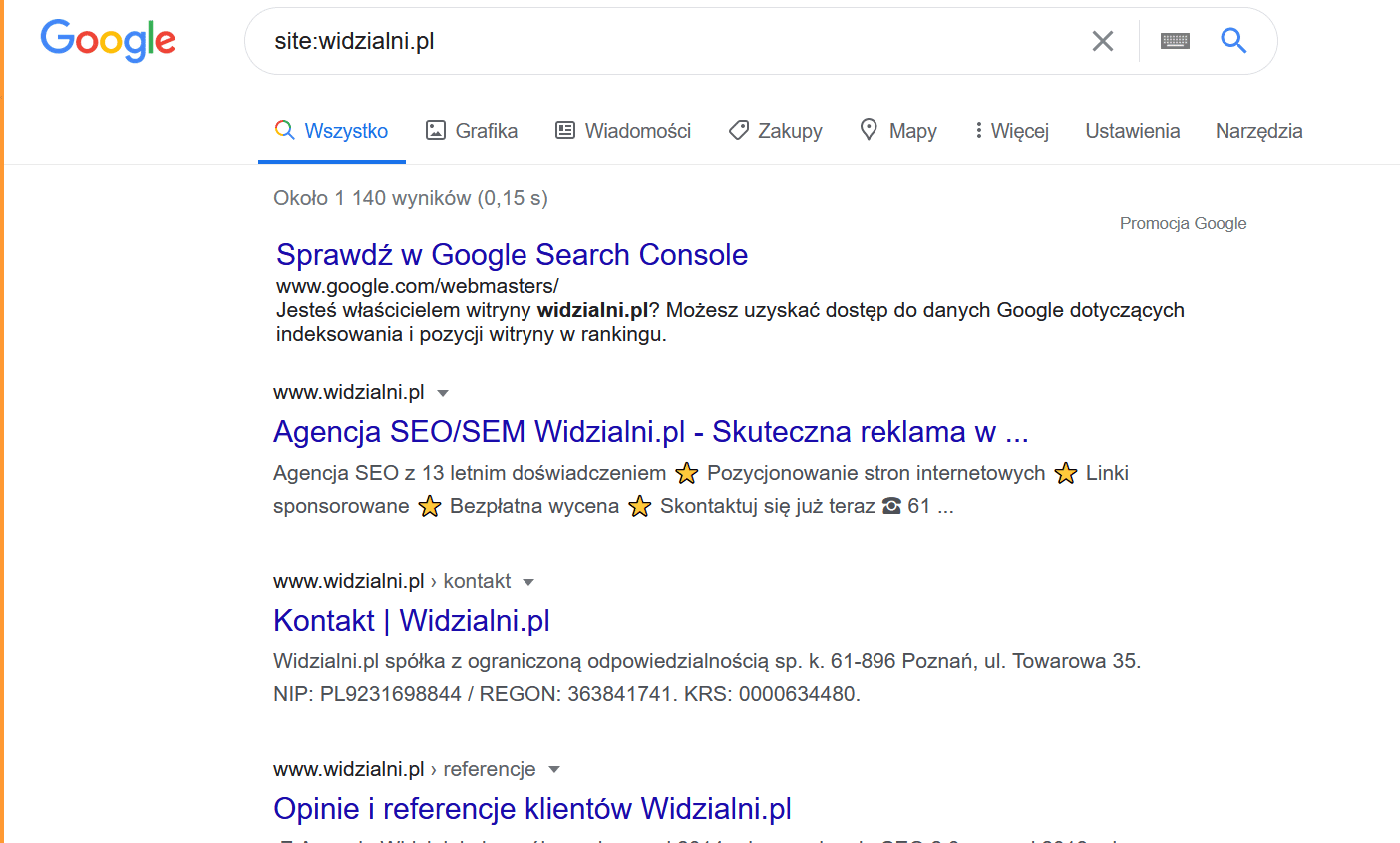
Na powyższym zrzucie ekranu przedstawiona jest strona wyników wyszukiwania Google dla zapytania o zaindeksowane podstrony z domeny widzialni.pl. Warto zwrócić uwagę, że Google nie prezentuje nam tutaj wszystkich danych, jakie zebrał i zaindeksował – pokazuje jedynie fragment danych, które najlepiej pasują do zapytania. Przechodząc na kolejną stronę wyników wyszukiwania, widzimy już inną liczbę wyników.
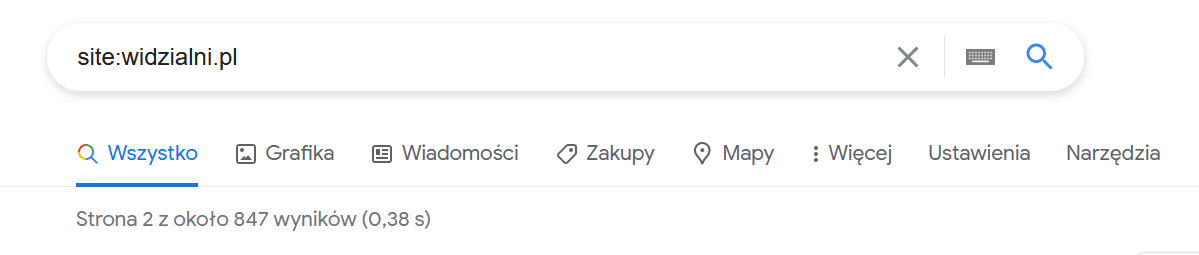
Dzieje się tak, ponieważ Google uznał, że dla drugiej strony wyników tego zapytania ograniczy pokazywane dane. Ograniczenie to czasem ma też nieco inny charakter – Google część podobnych do siebie podstron wrzuca do indeksu pomocniczego. Jest to miejsce, gdzie trafiają podstrony, które są łudząco podobne (albo wręcz stanowiące kopię 1:1) do innych stron w serwisie. Jeśli strona wpadnie do indeksu pomocniczego, z reguły nie da się jej znaleźć – tracimy więc pewien wolumen ruchu. W czasie audytu powieleń treści bardzo zależy nam na odkryciu takich właśnie stron.
O tym, czy jakieś zasoby trafią do indeksu pomocniczego, decyduje Google – nie mamy na to wpływu. Tylko dobra optymalizacja (w tym poprawa treści) może taką podstronę przywrócić do indeksu głównego. Indeks pomocniczy możemy zobaczyć przechodząc na ostatnią stronę wyników wyszukiwania dla zapytania site:domena.pl. Odnośnik do takiej strony pokazano na poniższym zrzucie.

Samo pojawienie się indeksu pomocniczego dla naszej strony nie jest niczym złym. Często zdarza się, że trafiają tam pojedyncze strony gorszej jakości, nierzadko pliki PDF stanowiące kopię serwisu. Jeśli jednak w tym zbiorze znajdują się strony z treścią, należy działać i skupić się na ich wyciągnięciu do indeksu głównego lub zablokować te strony przed indeksacją stosując meta tag robots noindex.
Google nie pokazuje nam pełnych danych o podstronach naszej witryny, które znajdują się w indeksie. Podobnie rzecz się ma ze znacznikami title – czasem to, co dostrzegamy w tym widoku, nie jest dokładnie takie samo jak w rzeczywistości. Warto o tym pamiętać w czasie dalszej analizy, gdyż następnym krokiem jest sprawdzenie jakie strony zapisał Google w swoim indeksie. Najlepiej jest nie robić tego w ten sposób, że każdą stronę trzeba otworzyć i zobaczyć co na niej jest, ale za pomocą analizy znaczników title, które widać na stronie z wynikami wyszukiwania.
Sprawdzając title szukamy anomalii, które znajdują się w indeksie. Mogą to być:
- zaindeksowane pliki np. PDF, doc, txt etc.,
- zaindeksowane subdomeny,
- strony administracyjne skryptów,
- wersje testowe artykułów lub wpisów,
- podstrony tagów.
Każda z takich stron powinna wzbudzić naszą czujność – może być ona nośnikiem powielonej treści. Tylko takie strony należy sprawdzić dokładniej, co znacznie skraca czas samego audytu. Zapewne okaże się, że część podstron nie będzie powielać treści, jednak takie analizy niemal zawsze kończą się znalezieniem potencjalnego problemu, którego wyeliminowanie znacznie wpłynie na zmianę stosunku treści unikalnej do powielonej.
Analiza site może być wykonywana ręcznie lub za pomocą narzędzi. Warto odpytywać site o różne kombinacje adresów w witrynie (np. z przedrostkiem www, bez www etc.). Dane zebrane w czasie takich odpytań mogą się różnić. Złożenie w całość danych z większej liczby zapytań pozwala odkryć więcej stron, które Google ma w swoim indeksie.
Kontrola wszystkich wersji witryny
Kolejnym krokiem po analizie site jest kontrola wszystkich wersji, pod którymi dostępna jest nasza strona. Jest to ważny krok dlatego, że Google rozpoznaje różne adresy naszej strony jako jej duplikaty. Jeśli ta sama treść jest dostępna pod wersją www.widzialni.pl oraz widzialni.pl, wówczas Google traktuje to jako powielenie treści.
Należy sprawdzić, czy strona jest dostępna pod różnymi wariantami – czy ma przekierowania do jednej z wersji oraz, czy po drodze nie występują błędy. Wersje strony, które należy sprawdzić to:
- wersja „bez www” np. http://widzialni.pl,
- wersja „z www” np. http://www.widzialni.pl,
- wersja „bez www z SSL” np. https://widzialni.pl,
- wersja „z www i SSL” np. https://www.widzialni.pl,
- wersja z wildcard np. http://nie.widzilani.pl,
- wersja z wildcard i SSL np. https://nie.widzialni.pl.
Jeśli wszystkie wyżej wymienione adresy prowadzą w to samo miejsce (w przypadku naszej domeny będzie to https://www.widzialni.pl/), wówczas nie musimy się obawiać o powielenie treści, które spowoduje dostępność takich samych treści pod różnymi wersjami.
Dla każdej z wyżej wymienionych wersji należy sprawdzić jakiego typu przekierowanie występuje pomiędzy adresem pierwotnym a docelowym. Warto do tego posłużyć się narzędziem o nazwie Web sniffer.
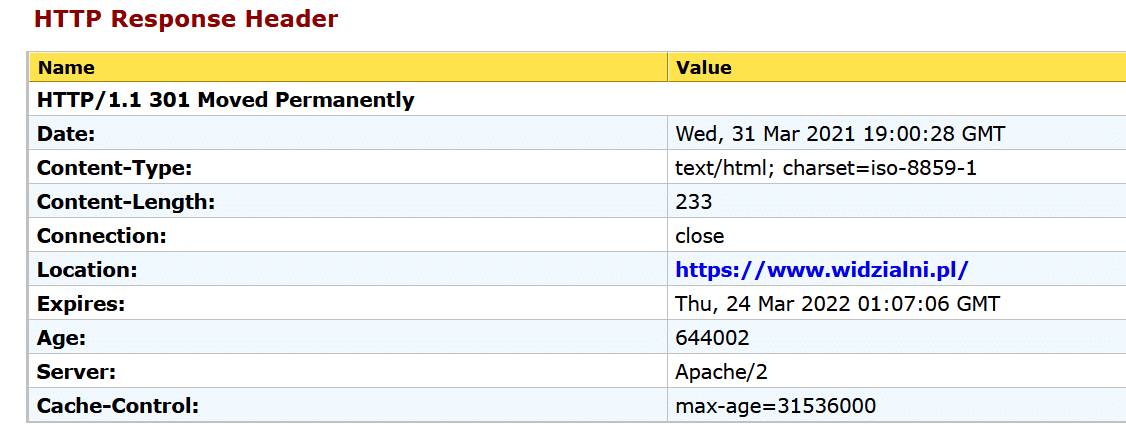
Na powyższym zrzucie ekranu pokazano wynik analizy przekierowań dla domeny widzialni.pl. Kod odpowiedzi serwera 301 oznacza przekierowanie stałe – jest to najlepszy rodzaj przekierowania patrząc z perspektywy SEO. Warto sprawdzić, czy przekierowanie jest typu 301 – jeśli tak nie jest, czasem zdarza się, że pomimo przekierowania można nadal zobaczyć niektóre zasoby witryny w indeksie wyszukiwarki.
Analiza treści wspólnych
Bardzo często zdarza się sytuacja, gdy w wielu miejscach witryny występują te same treści. Z poprzedniej części artykułu wiemy, czym jest powielenie wewnętrzne, znamy też zasadę stosunku treści unikalnej do nieunikalnej opisaną powyżej. W tym miejscu warto wspomnieć o efekcie skali. Bardzo krótki, powielony tekst na wielu podstronach serwisu może również powodować problemy z powieloną treścią na stronie, zwłaszcza w przypadku podstron, gdzie tej unikalnej treści brakuje.
Niemal na każdej stronie internetowej możemy się spotkać z takim przypadkiem. Przykładowo nasz blog posiada taką oto treść powieloną na wszystkich podstronach.
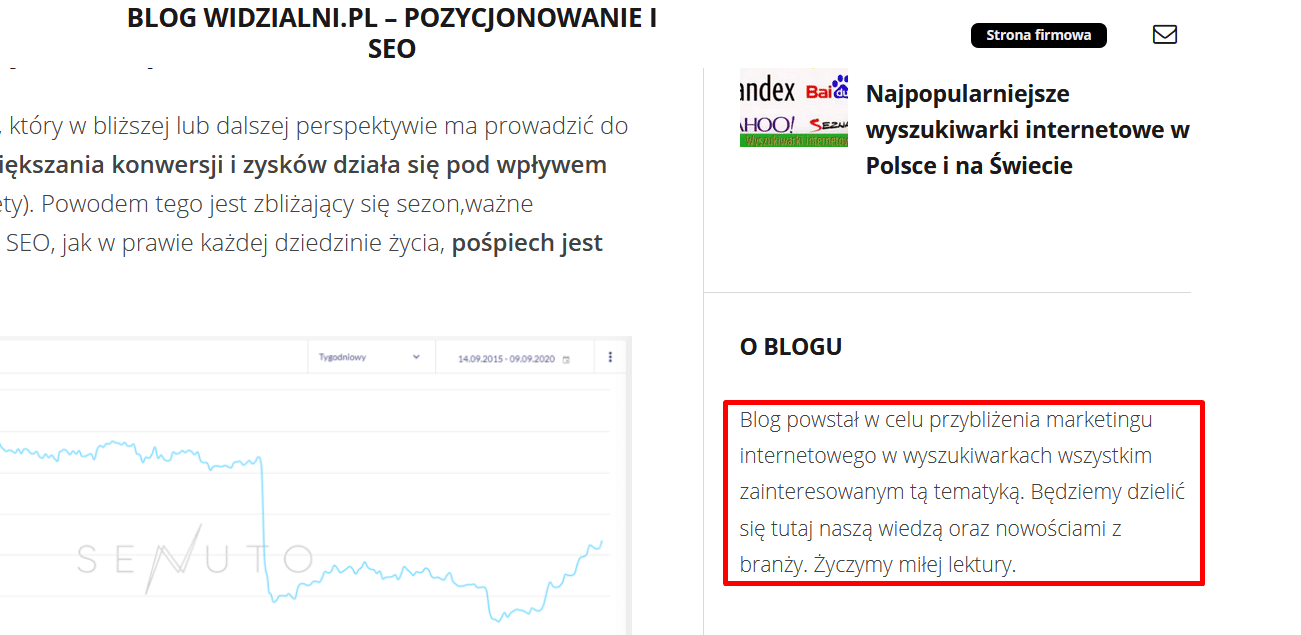
Tekst ma 202 znaki i w zestawieniu z unikalnymi i merytorycznymi artykułami na kilkanaście tysięcy znaków nie stanowi zagrożenia. Niemniej jednak jesteśmy świadomi jego istnienia.
Przykłady najczęściej powielanych treści w większości sekcji serwisu:
- informacje o cookies,
- krótka notka dot. strony,
- opisy w mega menu,
- informacje o koszcie i czasie dostawy.
W celu analizy treści wspólnych najlepiej jest otworzyć stronę w nowej, prywatnej karcie przeglądarki. Daje to pewność, że nie zostaną zastosowane nasze personalne ustawienia np. wynikające z obecności plików cookies.
Drugim krokiem jest wytypowanie typów podstron, które występują na naszej stronie. Zwykle w strukturze drzewiastej mamy strony kategorii → podkategorii → produktu. Do tego dochodzi podobna struktura na blogu oraz strony informacyjne, np. o nas, aktualności etc. Wykonując tę część prac można pominąć wszystkie strony, których nie ma w indeksie Google (takie ze znacznikiem noindex lub dyrektywą disallow).
Następnie należy sprawdzić i wypisać, jakie treści znajdują się na danej podstronie. Przykładowo dla dwóch podstron sklepu internetowego możemy uzyskać takie wyniki:
Podstrona 1
- opis kategorii,
- informacja o cookies,
- zajawki newsów.
Podstrona 2
- opis produktu,
- parametry produktu,
- opinie użytkowników,
- informacja o cookies,
- zajawki newsów.
Powyższe podstrony mają części wspólne, mianowicie informacje o cookies oraz zajawki newsów. Teraz należy sprawdzić, jaki jest stosunek treści powielonej do unikalnej, zwłaszcza na podstronach konkretnych newsów. Często to właśnie miejsce stanowi niemal 100% powielenia, gdyż news jest krótki i czasem cała jego zawartość mieści się w zajawce.
Gdy już mamy wytypowane części wspólne treści oraz ich wpływ na inne podstrony witryny, należy zaplanować czynności mające na celu eliminację powielonych wewnętrznie treści. Więcej na ten temat znajduje się na początku tego artykułu.
Analiza kanałów dystrybucji
Unikalne treści, które są tworzone na naszą stronę internetową, można samemu „zepsuć”, umieszczając je na innych, zewnętrznych stronach. Bardzo często dzieje się to nieświadomie, np. gdy napisane specjalnie dla nas, unikalne i nasycone frazami treści trafią do porównywarki takiej jak Ceneo czy Skąpiec. Autorytet tak dużego gracza mającego wielkie budżety na SEO i sztab ludzi jest w zdecydowanej większości lepszy niż autorytet naszej strony, co sprawia, że Google może uznać te treści za własność porównywarki cenowej, choć pochodzą one z naszej strony. Podobnie wygląda sytuacja w przypadku opisów dla aukcji na portalach aukcyjnych, np. Allegro.
Należy więc sprawdzić, czy w pliku wysyłanym do porównywarek znajdują się nasze treści. Najlepiej jest ich tam nie umieszczać bądź dostarczyć opisy od producenta, które i tak są powielone na innych stronach w sieci.
Podobną analizę należy przeprowadzić na firmowym profilu na portalu Facebook w celu sprawdzenia, czy nasze treści ze strony nie są tam powielone. Umieszczając wpisy na profilach w mediach społecznościowych, warto przygotować osobne przekazy marketingowe, dedykowane dla użytkowników danego medium – dzięki temu rośnie zainteresowanie naszymi treściami i pozbywamy się też powieleń treści ze swojej strony www.
Analiza adresacji kanonicznej
Adresacja kanoniczna pomaga robotom wyszukiwarki w określeniu, która z wersji strony jest ważniejsza i którą wersję powinno się pokazywać w wynikach wyszukiwania. Ta sama zawartość strony może (i powinna) występować w serwisie pod wieloma adresami. Linki kanoniczne zapobiegają powstawaniu powieleń, wskazując na pierwowzór treści.
Przykładem może być strona sortowania, gdzie użytkownik dostaje taką samą lub zbliżoną zawartość podczas wykonywania operacji sortowania produktów. Wskazując kanonicznie pierwowzór treści mamy pewność, że powstałe w ten sposób powielenia strony nie wpłyną negatywnie na jej ocenę przez roboty Google. W trakcie crawlowania strony adresacja kanoniczna jest respektowana przez algorytmy Google, co więcej – jeśli jej brakuje, to mechanizmy wyszukiwarki mogą same wskazać kanoniczną wersję podstrony.
Adresy kanoniczne są zaszyte w kodzie każdej podstrony i nie są widoczne dla zwykłych użytkowników (z których spora część pewnie nawet nie wie o ich istnieniu). Powinny się znajdować w sekcji head każdej podstrony.
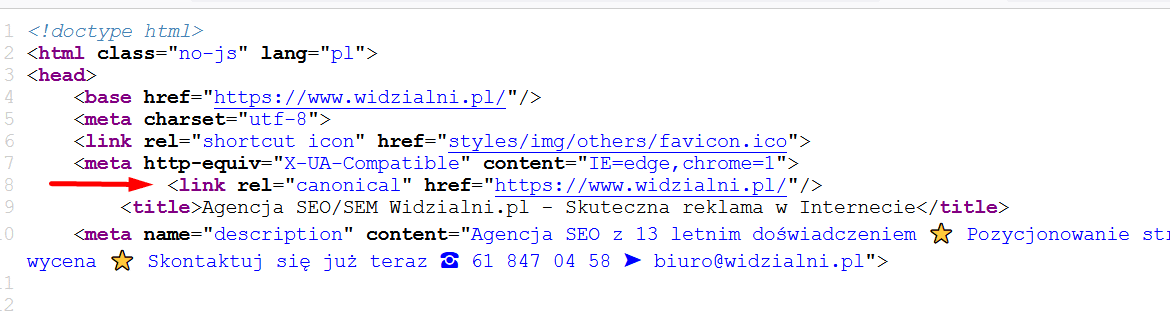
Celem audytu adresów kanonicznych pod kątem powielenia treści jest sprawdzenie, czy:
- na każdej podstronie jest ustawiony adres kanoniczny,
- jest on poprawny (wskazuje tą podstronę, odpowiednią wersję np. https:// etc.),
- czy na stronach sortowania i filtrowania wskazuje pierwowzór treści (np. czysty adres strony kategorii).
Wykonanie audytu treści na stronie pozwala na sprawdzenie, czy treść nie została skopiowana oraz, czy z technicznego punktu widzenia, nie ma problemów, które mogą wpłynąć na ocenę treści. W trakcie przeprowadzenia takiego audytu można natrafić na wiele błędów, które utrudniają pozycjonowanie. Poprawa tych błędów często przekłada się na wzrosty ruchu i pozycji strony internetowej.
Brak sekcji




Duplicate content to paskudna sprawa. Co prawda krążą na ten temat mity i opowieści, ale uważam, że treść powinna być absolutnie unikalna.
Dzień dobry, chciałabym się dowiedzieć, co zrobić, gdy strona główna /blog wyświetla się na frazy kluczowe? Dochodzi do takiej sytuacji, że na frazę kluczową nie wyświetla się konkretny artykuł pisany pod tę frazę, a właśnie strona ogólna /blog?